En su libro Los innovadores, Walter Isaacson deja muy clara una premisa que han compartido los avances más destacados en informática: los grandes genios pueden existir, pero es muy improbable que sus ideas consigan prosperar a menos que tengan una red de colaboradores, equipo, colegas a su lado. Y esto es sencillo de entender: una gran idea es sólo eso si no se ejecuta. El poder ejecutarla de forma adecuada va a depender, casi siempre, de la capacidad que tengas de «utilizar» esa red. Hay varios ejemplos claros en el libro, pero quedáos con la idea de que las ideas clave funcionaban cuando se tenía una infraestructura de trabajo por detrás (que normalmente iba a ser ingeniería que «montase» la idea), y no cuando al «genio» se le encendía la bombilla. De hecho, muchas de esas bombillas se guardaron en un cajón para nunca más volver e encenderse por esa manía de querer ser el lobo solitario brillante.
Pues bien, basándome en las ideas de este libro, el artículo de hoy va un poco dedicado a hacer crecer esa red, de «aprovecharnos» todo lo posible de esa red ampliando nuestro territorio y divirtiéndonos por el camino. Por supuesto, y como suele ser ya habitual en este blog, para ejemplificar el proceso vamos a usar datos de música. En particular, mi misión aquí es comprobar una hipótesis que tengo desde hace tiempo: ¿ha conseguido el reggaeton desbancar al inglés como idioma predominante en la música popular del mundo?
No nos centremos en la pregunta, sino en el proceso que vamos a seguir para obtener las respuestas. Porque aunque la información en sí misma no nos va a ser muy útil para nada (a vosotros, a mi frikismo musical mucho), las herramientas de las que nos vamos a servir son un algo potentísimo que siempre vamos a poder utilizar. En concreto, lo que vamos a ver en este artículo es cómo configurar y usar:
- Google Cloud Functions
- Google Cloud Schedule
- Google Big Query
Para realizar nuestro ejemplo práctico utilizaré datos extraídos de la ya habitual API de Spotify, concretamente de las que contienen el top 50 de canciones por país (sí, he hecho un diccionario con esto, así soy de freak). Por entendernos, el proceso en realidad es muy sencillo: quiero extraer todos los días la información de todas estas playlists (qué canciones contienen y en qué puesto están y almacenar esto en una tabla de BQ que ya he generado previamente. ¿Para qué? Para poder comprobar cuáles son las canciones que mejores puestos han acumulado durante el periodo de tiempo analizar y, gracias a esto, entender si en realidad son las canciones en español las que acumulan más y mejores oyentes o no.
Poco importa, en cualquier caso, la frikada que se me haya ocurrido para probar este sistema. Lo importante de todo esto es el proceso que nos permite, con 4 trastos, montar un circuito a través del cual tendremos corriendo lo siguiente todos los días:
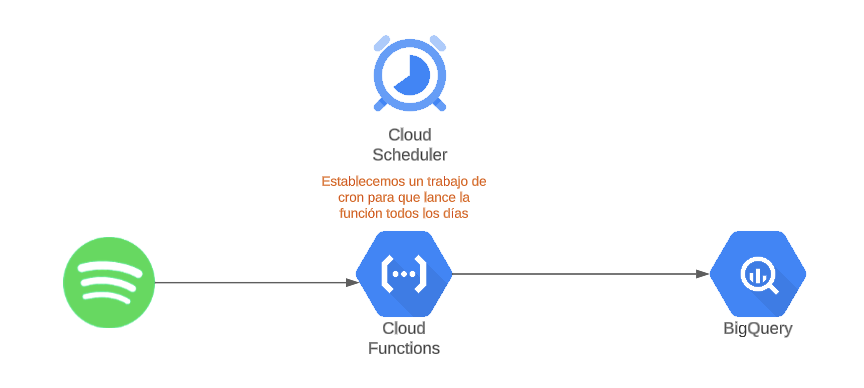
Entendéis las posibilidades de esto, ¿verdad? Exacto, con esto somos capaces de integrar en nuestro BQ cualquier dato que podamos extraer de una API. Y, con el esquema adecuado, enriquecer nuestros datos de GA4, por ejemplo.
En este caso, el proceso que he seguido es muy sencillo, más allá de generar la función de python con la que se recoge toda la info (con todo el diccionario para cada una de las playlists de países…), lo demás es bastante straightforward. Generamos la tabla en BQ:

- Generamos un nuevo dataset, en mi caso con el nombre de spotify.
- Dentro de este dataset, generamos una nueva tabla, que contendrá los valores que queremos extraer con nuestra function
- Editamos el schema de esta tabla
- Dejamos algo parecido a esto en el schema.
En nuestra función, una vez ya tenemos el dataframe que queremos cargar en BQ, haremos algo parecido a esto:

De esta forma, con la configuración de escritura append indicamos que toda la nueva información se debe añadir a lo existente, no sobreescribir.
Por último, configuramos nuestro trabajo de cron:

Listo, toda la info que queremos de Spotify se va a cargar todos los días a las 9 en nuestra tabla de BigQuery. Los resultados los podemos consultar en Looker, por ejemplo:

En este caso, lo que he podido ver es que, aunque no ha desbancado por completo a la música en inglés, sin duda el español está en camino, con 5 de las 10 canciones con mayores puestos altos en el periodo analizado a nivel global.
¿Que esto lo podemos hacer sin el cloud de Google (u otro)? Sí, pero no. No hay forma de hacer esto de forma TAN sencilla. Un poco de python en functions, un scheduler y voilà: ya tenemos algo que nos permite almacenar datos diariamente de forma ilimitada. Más allá de lo presentado aquí, las opciones son prácticamente infinitas, up to you.
Y ya está, esto es lo que quería contaros. Sólo pensad en la cantidad de cosas que se pueden añadir a vuestra información básica (datos meteorológicos, financieros, trends…) gracias a un proceso como este. Espero que os sirva y lo disfrutéis.
