Este blog poco a poco empiezo a parecer algo decente, y es que con esta ya van 10 entradas publicadas. Teniendo en cuenta el tiempo que me cuesta escribirlas, me parece todo un logro. Que quiera hacerlo con esta entrada no es casual: Pandas es una de las herramientas más útiles y utilizadas en el campo del análisis de datos. Pero no entremos todavía en la herramienta, quiero explicaros de que va a tratar esta entrada.
No esperéis aquí una guía de cómo utilizar Pandas, no es esa mi intención. Para eso está documentación de Pandas que, además, cada vez es más amplia. Lo que quiero aúnar aquí son todas las funcionalidades y técnicas que, con el paso del tiempo, he visto que son las más útiles a la hora de limpiar y organizar los datos que quieres trabajar. Por simple cuestión de comodidad, he partido la entrada en dos, por lo que en esta primera encontraréis las técnicas más relacionadas con limpieza de datos, mientras que la segunda versará sobre la organización y estructuración de los mismos. Algunas serán básicas y otras algo más complejas, pero os garantizo que si domináis todas ellas preparar vuestros datos para el análisis no será un problema (el problema, como siempre, vendrá después). Vamos allá.
¿QUé es pandas?
Para empezar, vamos a intentar entender primero de lo que estamos hablando. Pandas es una biblioteca de Python, desarrollada a partir de su otra biblioteca de computación matemática NumPy. Y, ¿qué es lo que hace especial a Pandas? ¿Por qué no quedarnos con NumPy? Pues básicamente porque lo que se ha intentado (y normalmente conseguido) con Pandas ha sido desarrollar una biblioteca que facilite la vida al analista de forma exponencial. Así, mientras el campo de acción de NumPy es mucho más limitado (se encarga de crear vectores o matrices, funciones matemáticas, etc.), Pandas es un atrapatodo. Me gusta pensar en Pandas como el Excel del siglo XXI, y es que tienen muchas cosas en común, siendo la más principal su vocación en convertirse en una herramienta indispensable -y «sencilla»- para cualquiera que quiera trabajar con datos.
Con Pandas puedes desde leer un csv o json tanto de local como de una url en una sola línea hasta realizar operaciones propias de SQL o lanzar y extraer datos de bases de datos, desde MySQL hasta Bigquery. Las integraciones que tiene Pandas son ya prácticamente infinitas, lo que facilita mucho las cosas a la hora de realizar conexiones o probar nuevas herramientas. La unidad básica de trabajo en Pandas se llama DataFrame y normalmente siempre trabajaremos alrededor de esta. Es muy interesante observar la documentación de Pandas para entender cómo se pueden generar los Dataframes, ya que pueden surgir de diversas formas. Si tu área de trabajo habitual ha sido Excel y sus variantes, el DataFrame te será como un antiguo conocido, ya que es también una tabla de 2 dimensiones, con etiquetas para cada columna y posibles diferentes formatos para cada una de ellas.
Por supuesto, no es para nada una herramienta perfecta, y sin dudar de su utilidad, hay veces que será preferible utilizar otro tipo de recurso. Para mí, los problemas fundamentales que presenta son dos: su poca legibilidad y la capacidad limitada de tratamiento de datos debido a problemas de memoria. Aclaro esto un poco: aunque es cierto que la sintaxis de Pandas es sencilla y te permite realizar tareas en menos líneas de código, también es cierto que esta sintaxis poco o nada tiene que ver con Python y que muchas veces se hace muy dificil seguir el trabajo de otro analista. Pongo un ejemplo gráfico que se entenderá perfectamente (por cierto, muchas de las funcionalidades que vamos a ver están en este snippet):

Creo que queda muy claro de lo que hablo. Ese código lo he hecho yo y hay veces que vuelvo y no sé para qué servía. Tengo que mirarlo en profundidad y ver la relación entre las distintas variables. En cambio, si observo otro que no está utilizando pandas como lenguaje primario sino lo básico de python, queda mucho más claro el propósito del código:

Por otro lado, a la hora de procesar grandes volúmenes de datos Pandas se puede llegar a estresar ya que está constreñido por unas limitaciones de uso de memoria que pueden dar lugar a errores en tu flujo de datos. Todo esto dependerá de la máquina en lo que lo utilices (ya se a local o cloud), pero en la regla general para que Pandas pueda trabajar sin problema con el dataset es que tengas una capacidad de al menos 5 veces el tamaño de tu dataset. Es decir, si tu conjunto de datos tiene un tamaño de 5g, tu RAM deberá ser de al menos 32GB. Por supuesto, esto es un auténtico problema si tu dataset tiene por ejemplo 1TB. Esta regla no me la he inventado yo, sino el propio creador de Pandas, Wes McKinney. En este MUY interesante artículo, McKinney extrae todos los problemas que ha ido encontrando desarrollando y trabajando con Pandas. Como veréis, él encuentra mucho más problemas que yo, y estos problemas tienen la mayoría su base en el tratamiento de grandes volúmenes de datos. Y aunque estoy de acuerdo con él en todos sus puntos, no esetá más añadir que la mayoría de ellos sólo se muestran si estás intentando analizar volúmenes gigantescos de datos. Y esto no va a pasar en la mayoría de ocasiones.
Con esto no quiero echar para atrás a nadie en el uso de pandas ya que es una herramienta utilísima, pero creo que es importante que se entienda cuáles son las limitaciones de la herramienta y derivado de ellas, tener claro cuáles son sus casos de uso más apropiados.
Técnicas de limpieza de datos
Vamos a empezar primer con las técnicas que nos ayudan a limpiar los datos con Pandas. Es bueno empezar con esto porque será lo primero que hagamos una vez hemos obtenido los datos. Vamos a imaginarnos esta situación: trabajas para una compañía que se dedica generar profecías para la gente de a pie, la llamaremos «The Prophecy». Por supuesto, cada profecía tiene su propio identificador único, que está asociado a la persona que la ha solicitado. Lo tienen todo almacenados en DataFrames de Pandas (su unidad de trabajo más básica). Con este imaginario en mente, podemos generar una muestra de lo que sería nuestro dataset para empezar a trabajar:

Replace
Como podéis ver, nuestro DataFrame es muy simple: consta de dos columnas, una de ellas con la profecía en sí misma y la otra con el nombre de la persona para la cual se ha generado. Pues bien, el problema que nos encontramos aquí es que algunas de las profecías tienen el carácter «[» dentro de su string. Por supuesto, no podemos entregar de esta manera esto a nuestros clientes, por lo que nos tocará hacer un poco de limpieza de datos para solucionarlo. Para ello, vamos a utilizar el método «str.replace» que está asociado el tipo Serie dentro de Pandas. Al tratar los datos como una Serie, debemos tener claro que no estamos modificado todo el DataFrame, por lo que tenemos que especificar a Pandas qué es lo que vamos y queremos cambiar:

Creo que aquí ya se entiende lo que estamos haciendo, pero lo especifico: estamos diciendo que la columna «prophecies» del DataFrame «prophecies» ahora es igual a la operación de reemplazo que hemos hecho, donde estamos diciendo que cuando se encuentre con el carácter «[» o «]» debe sustituirlo por un string vacío. Si observamos de nuevo nuestra tabla con el comando head(), veremos qué ha ocurrido:

Vale, parece que ha funcionado justo como esperábamos. Ya no tenemos los caracteres molestos que nos estaban lastrando. En este sentido, aunque quizá no se utilicen tanto, vale la pena mencionar las funciones strip() y split(). La primera la podemos utilizar tanto para eliminar espacios en blanco o saltos de línea molestos. La segunda es capaz de crear elementos diferentes en una lista diciéndole el caracter a través del cual debe hacerlo. Por ejemplo, si tuviéramos una frase llena de comas podríamos decirle que todo lo que se encuentra entre comas sea un elemento de una lista.
Pop & Drop
La mayoría de las veces, nos encontraremos con conjuntos de datos de los cuales no nos interesa toda la información de la que están compuestos. Por ello, es muy útil saber utilizar debidamente los comandos Pop & Drop. Comencemos por el más utilizado y más sencillo en su funcionamiento: drop. Con esta función somos capaces de eliminar de golpe columnas o filas de nuestro DataFrame. En este caso, nuestro ejemplo tiene una columna que no nos interesa mantener, llamada convenientemente «useless_column»:

Como veis, han aparecido nuevas columnas en nuestro conjunto de datos. Lo que queremos hacer ahora es eliminar por completo la columna que no nos interesa para así poder trabajar los datos de forma eficiente. Si hacemos lo que nuestro instinto nos dice, escribiríamos algo parecido a esto:
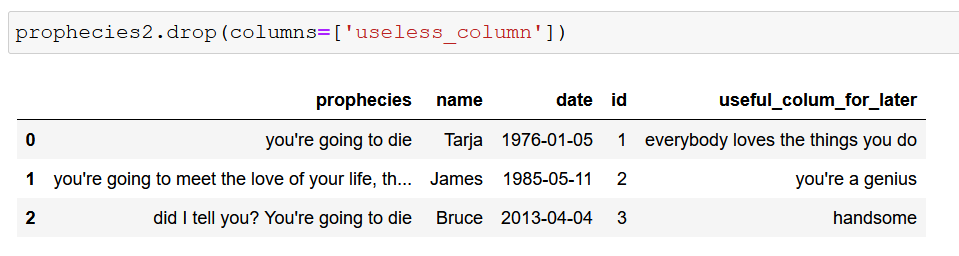
Parece que la cosa ha funcionado como queríamos, pero atención a esto porque es un punto importante. Si llamos de nuevo a nuestra DataFrame, lo que obtenemos es lo siguiente:

¡La columna ha vuelto a aparecer! Bueno, en realidad esto no es así, sino que el funcionamiento por defecto de Pandas hace que el Dataframe original no sea modificado a no ser que sea explícitamente especificado. La tabla que hemos vistoa nteriormente en la que la columna había desaparecido en realidad se trataba de una copia que Pandas realiza para tal cometido. Por ello, para poder trabajar con la tabla modificada tenemos dos opciones: o almacenar esa copia en una variable o utilizar el método «inplace»:

Siguiendo la misma lógica que habíamos empleado anteriormente, podemos ver cómo ahora sí se ha modificado el interior de nuestro DataFrame original, gracias a especificar que, en este caso, el inplace era True. Esto le dice a Pandas que queremos modificar el contenido del Dataframe original, haciendo que la columna desaparezca tal y como queríamos.
Por otro lado, tenemos la función .pop() que realiza una función muy parecida a drop, pero con una lógica distinta. Lo que hace pop es extraer la columna seleccionada del dataframe que queramos, lo que nos permite utilizarla más tarde si ese fuera nuestro objetivo. En nuestro ejemplo teníamos una columna que no queríamos ahora, pero que necesitaríamos más tarde, por lo que podemos utilizar pop para guardarla:
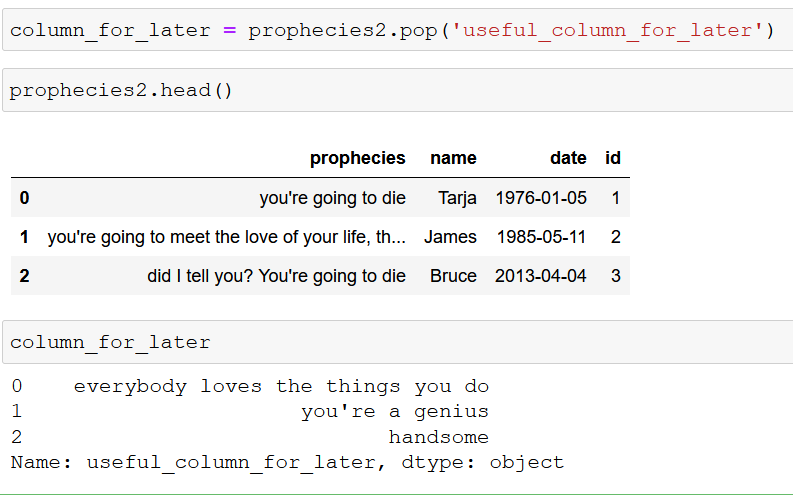
En este proceso que tenemos arriba lo que hemos hecho ha sido extraer la columna «useful_column_for_later» de nuestroDataFrame original y y guardarla en una variable que podamos utilizar más tarde. Como véis, al llamar a esa variable nos devuelve los valores que se correspondían con los de esa columna en la tabla original. Más tarde veremos cómo podemos recuperar esta columna e integrarla con nuestra tabla.
Convertir formatos
Uno de los problemas más fundamentales que nos vamos a encontrar SIEMPRE cuando trabajemos con cualquier conjunto de datos es que los formatos no sean los adecuados para realizar nuestro análisis. Pandas ya sabe que esto ocurre y ha desarrollado una serie de recursos para ayudarnos a ejecutar esta tarea de forma mucho más sencilla. La mayoría de estas funciones toman la forma de to_»something», siendo este something desde un formato numeric hasta datetime. En nuestro ejemplo vamos a centrarnos en el caso de convertir los datos a formato fecha porque suele ser lo más habitual. La lógica para realizar esto al resto de formatos sigue exactamente la misma línea.
Siguiendo con nuestro ejemplo, nos damos cuenta que tenemos una columna «date» que no está en el formato fecha que queremos. Gracias al comando dtypes, podemos observar los formatos correspondientes a todas las columnas:

Ahora mismo el formato de date es object, lo cual nos dice que pandas lo está reconociendo como string. Aunque ahora mismo no nos afecta demasiado para observar los datos, una vez intentamos realizar algún tipo de operación que contenga fechas vamos a tener problemas. De hecho, vamos a observarlo de manera gráfica. Si realizamos un pequeño chart con los datos de id y fecha de creación, nos saldrá algo como esto en estos momentos:

En cambio, si realizamos el cambio de formato tal y como nos gustaría que fuese gracias al comando «to_datetime», la cosa cambia mucho (aunque esta sea una muestra muy pequeña):

Ahora sí, los datos se comportan tal y como queríamos, ya que se estructuran de forma escalanda y se integran en una línea temporal lógica. Además, si observamos los tipos de nuestro DataFrame, veremos cómo este se ha transformado:

Gracias a esto, ahora tenemos un conjunto de datos que podemos organizar a través de la fecha en la que ocurren los diferentes eventos.
conclusiones
En esta primera parte de este artículo hemos visto las prácticas que yo considero más útiles a la hora de limpiar datos dentro de Python con Pandas. Estas técnicas se encargan principalmente de convertir los formatos de los datos para que más tarde podamos utilizarlos de forma dinámica; eliminar columnas o filas tanto en memoria como permanentemente o extraer columnas para poder utilizarlas más tarde (en la siguiente parte veremos como agregar esas columnas de nuevo) o hacer una sustitución de caracteres en los campos que integran nuestra tabla para eliminar todo aquello que pueda interferir en el análisis posterior.
Por otro lado, también hemos visto qué era exactamente Pandas, cuándo lo podemos utilizar, y cuáles son sus mayores limitaciones, algo que nos ayudará a elegirlo como compañero de viaje en los trayectos adecuados. En la siguiente parte veremos las técnicas que considero más importantes a la hora de organizar y estructurar de la mejor forma nuestros datos, además de publicar el jupyter notebook que contiene todo el código utilizado, os espero por allí.
