Si has llegado hasta aquí sin duda eres uno de los míos: los datos te atrapan más que una pizza el sábado por la noche. Como ya comenté en la primera parte de este post, esta segunda parte versaría sobre las técnicas que considero más útiles y fundamentales a la hora de estructurar nuestros datos. Tengo que confesaros que, aunque la primera parte (la limpieza) es completamente indispensable en cualquier problema, es en esta parte donde las cosas se empiezan a poner interesantes. Donde puedes empezar a jugar con los datos de verdad.
Join
¿Os acordáis de la columna que habíamos extraído y guardado anteriormente de nuestro DataFrame? Este va a ser el momento en el que la recuperemos y la integremos de nuevo en nuestro conjunto de datos como si nada hubiera pasado. Además, en pos de acelerar los posteriores procesos, también vamos a añadir una columna nueva, que vamos a llamar «prophecies_types» porque integra el tipo de profecía que se ha generado.
Pero antes de llegar a eso, expliquemos un poco la técnica que vamos a utilizar: join. Join funciona de forma muy parecida a como se comporta en SQL, pero tiene una diferencia fundamental por la cual prefiero utilizar merge (que veremos más adelante) para uniones entre diferentes DataFrames: las uniones se realizan en base a los índices. Pero para realizar procesos como el que tenemos a continuación funciona perfectamente bien. Lo que queremos básicamente es agregar la columna que habíamos extraído y la nueva a nuestro Dataframe. Funcionaría como algo parecido a esto:

Vale, varias cosas aquí: como véis, la técnica ha funcionado a la perfección, ya tenemos las dos columnas que necesitábamos en nuestro DataFrame. Pero hay que especificar ciertos aspectos que tenemos que tener en cuenta cuando estamos haciendo este tipo de proceso: lo primero de todo, si vamos a añadir una nueva columna a nuestro DataFrame es mucho mejor que lo hagamos a través de una serie de Pandas. Esto nos evitará muchos problemas más tarde. Por otro lado, debemos especificar que ahora nuestro DataFrame va a ser la unión del antiguo con las dos nuevas columnas, por lo que lo almacenaremos en esta variable de nuevo.
Por último, el proceso de split lo que nos permite es obtener los elementos de prophecies_types en una lista con sus elementos diferenciados. Esto lo hacemos específicamente para poder acercarnos a nuestra próxima técnica, una de mis favoritas: explode.
explode
Explode, por decirlo en pocas palabras, te permite denormalizar un Dataframe en base a una columna o varias. ¿Esto qué quiere decir? Pues tomemos nuestro ejemplo y creo que se entenderá muy rápidamente: tenemos que calcular el total de profecías que se han generado con el tipo «dying». Si tomáramos nuestro conjunto de datos tal y como está ahora, sólo obtendríamos 1 de esas profecías, ya que la asociada a Tarja contaría como tipo «dying, loving» y se saltaría nuestro criterio. Por tanto, para poder realizar nuestra operación de forma adecuada más tarde, deberemos denormalizar nuestro conjunto a través de la técnica Explode. Y la verdad, no puede ser más sencilla de implementar:
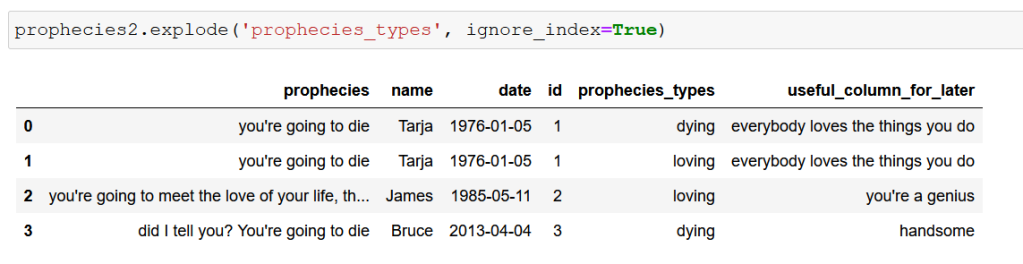
¿Véis lo que ha ocurrido? Básicamente se han duplicado las filas que tienen diferentes elementos en «prophecies_types» con el resto de columnas completamente idénticas. Esta técnica es tremendamente útil cuando estás tratando con elementos que tienen diferentes especificiones a las que pueden pertener al mismo tiempo (canciones que pueden pertenecer a varios géneros musicales a la vez, profecías que se pueden enmarcar en diferentes categorías en conjunto…).
MAP
Para mí, que mis primeros contactos con el análisis de datos vinieron de la mano -como creo que de la mayoría de nosotros- de nuestro gran aliado Excel, la función de Pandas map() fue como encontrarse con un viejo amigo que siempre te ha tratado con mucho cariño. ¿Por qué digo esto? Pues básicamente porque map actúa de forma muy similar al vlookup de toda la vida, pero por supuesto, en el entorno python.
Cuando veamos el siguiente ejemplo váis a entenderme enseguida. Imaginad que en lugar de agregar la nueva columna sobre tipos de profecías, lo que nos dan es un diccionario que relaciona la persona de la profecía con el tipo que se le ha generado. Lo mejor para poder crear nuestra nueva columna sería tener una herramienta que nos permitiese relacionar ese nombre dentro de nuestro dataframe con el del nuevo diccionario y que nos devolviese el valor asociado, ¿verdad? Pues eso es justamente lo que hace .map().
En la imagen podéis observar como funciona. La primera parte es simplemente la generación del nuevo diccionario y la eliminación de la antigua columna «prophecies_types» (os acordáis de cómo usar .drop()?). En la segunda parte ya nos encontramos le proceso de map completo: creamos una nueva columna llamada «prophecies_types» (sí, en pandas es así de sencillo crear una columna nueva) y le decimos que es igual al map de «name» con nuestro diccionario. Si mostramos la nueva tabla, observamos cómo obtenemos exactamente lo que queríamos.

No puedo evitar sentir devoción por esta función, y creo que es tremendamente útil a la hora de establecer vínculos entre diferentes conjuntos de datos.
merge
Por fin llegamos a, posiblemente, la función más importante a la hora de organizar datos dentro de Pandas: merge. Si habéis trabajado con SQL en alguna ocasión sabéis lo importantes que son los joins (inner, left, right, outer…) a la hora de generar relaciones entre diferentes conjuntos de datos. Gracias a ellos, podemos unificar en una tabla diferentes elementos en base a uno o varios criterios. Esto es fundamental para poder trabajar correctamente los datos más tarde. En resumen, lo que los joins de SQL realizan se puede entender de esta manera:

Pues bien, la función merge se encarga de hacer las mismas operaciones con nuestros DataFrames, lo que nos facilita la unión de forma considerable si no queremos cambiarnos a SQL mientras trabajamos en python (por otro lado algo recomendable en algunos procesos). La sintaxis es bastante sencilla una vez te acostumbras a ella (mucho más legible que en SQL, algo que no era complicado tampoco) y puedes especificar cosas como la columna (o columnas) a través de las cuales quieres realizar la unión, el tipo de unión que debe realizar, etc.
Vamos a ver el ejemplo que hemos preparado para entenderlo correctamente. Nos han dado un DataFrame nuevo, en el cual encontramos dos columnas: el nombre (un valor único de identificación) de la persona a la cual se le ha generado la profecía y unas especificaciones especiales de esa profecía en concreto. Se nos ha pedido que extraigamos cuándo se han producido exactamente esas profecías y que especificaciones tienen. Por tanto, nuestra única solución viable es realizar una unión de nuestros dos DataFrames para tener toda la información disponible en una tabla de la que poder extraer esa información.
Como veis en la imagen primero hemos creado este nuevo DataFrame. Fijaos que tenemos un nombre que no existe en nuestro DataFrame actual («Chuck»), lo cual va a ser interesante a la hora de realizar nuestras operaciones. En el segundo proceso ya nos encontramos con el merge. Mirad la sintaxis porque en realidad es muy sencilla:
dataframe1.merge(dataframe2, on=(columna a través de la cual se va a realizar el join), how=(tipo de unión, en nuestro caso escogeremos 'inner')
Si completamos esta sintaxis con los parámetros de nuestro ejemplo, lo que obtenemos es la tabla final que podemos observar en la imagen:

¿Véis que ahora la tabla tiene sólo 2 columnas? Esto ha ocurrido porque hemos realizado el merge con el tipo de unión «inner». Esto quiere decir que sólo unifica las columnas si encuentra el identificar an ambas. Como James no existe en nuestro nuevo DataFrame, y Chuck no existe en el antiguo, se han eliminado de nuestra nueva tabla, ya que no se pueden relacionar de esta manera.
En las conclusiones os voy a dejar el Jupyter Notebook que he trabajado para realizar esta serie de técnicas, por lo que os voy a poner una tarea para practicar: ¿Qué pasaría si utilizáramos otro tipo de uniones? Tratad de crear nuevos DataFrames con uniones diferentes y observad como cambian los datos.
conclusiones
En este artícuo en dos partes hemos podido ver las que considero las mejores técnicas para limpar y organizar datos con Pandas y python. Esta entrega se ha centrado en la parte de organización y estructura, en la cual hemos aprendido principalmente:
- Cómo agregar nuevas columnas o Pandas Series a nuestro Dataframe original a través de la indexación.
- Cómo denormalizar nuestro DataFrame a partir de los valores de una columna (previamente transformada en elementos de una lista)
- Cómo agregar nuevas columnas a nuestro Dataframe utilizando una función que nos permite buscar correspondencias entre dos elementos y apuntar a su valor.
- Cómo realizar uniones a la manera de SQL entre dos DataFrames.
Espero que toda esta recopilación os haya sido útil, ya que para mí son mis técnicas de cabecera, y me encantaría conocer las vuestras si las tenéis. Como ya os he comentado, os dejo aquí el jupyter notebook que he trabajado para que podáis explorarlo y jugar con él. No os olvidéis de realizar la tarea que os he propuesto! Os leo en comentarios.
