Comienzo esta entrada con la intención de crear una sección: API Calls. Dado que las API son una de las herramientas más fundamentales a la hora de extraer datos que necesitamos y nos permiten hacerlo de forma programática, qué mejor que dedicarles una sección. Iremos viendo diferentes tipos de API, cómo realizar las llamadas y cómo organizar los datos. En el caso que nos ocupa vamos a adentrarnos de lleno en el corazón de los datos de uno de los CRMs más importantes del planeta: Hubspot. Esto va a ser una exploración digna de los mejores libros de Joseph Conrad, así que espero que me acompañéis hasta el final y no os perdáis entre las tinieblas. He decidido dividir este proceso en dos entradas separadas porque iba a ser mucho para digerir en un solo texto. Estas son las paradas que vamos a ir realizando en esta primera exploración:
Las primeras dos paradas son obligatorias para todos aquellos de vosotros que no conozca de lo que estamos hablando, para el resto, volad hasta el tercer punto sin mirar atrás.
¿Qué es una API?
A ver, no os voy a dar aquí una explicación académica de lo que es una API, pero sí conviene hacer algunas aclaraciones antes de empezar la travesía. Las siglas API vienen específicamente de Application Programming Interface, y define un elemento en computación que sirve para detallar las posibles interacciones entre diferentes componentes de software. Para intentar sintetizar esto de una manera más comprensible, imaginad esto:
Llegas a un hotel y tienes una serie de peticiones que realizar al recepcionista. Por ejemplo, necesitas que tu almohada esté hecha exclusivamente de plumas de Dodo y que el desayuno se te sirva exactamente a las 7:42. El recepcionista toma nota de tus peticiones y hace una comunicación con los diferentes departamentos (cocina, almohadas) para que sean satisfechas.
Así, el recepcionista de este ejemplo sería la API, ya que se encarga de recoger una serie de peticiones, transmitirlas en un formato entendible para los diferentes departamentos (el sistema del cual queremos extraer información o al que queremos dar órdenes) y encargarse de esas peticiones sean devueltas al cliente.
El campo de utilización de las API es muy amplio, pero en este caso concreto (y en el resto de entradas de esta sección) nos centraremos en el uso más común de ellas: las Web APIs (en nuestro caso, RESTful APIs). El funcionamiento es exactamente el mismo que el que hemos descrito en el caso del recepcionista, vamos a realizar una llamada a una web (Hubspot) y le vamos pedir una serie de datos, que la web nos devolverá en el formato que nos indique la documentación. Esta petición la haremos a un «compartimento» específico de esos datos, algo que se llama endpoint. Será nuestro trabajo posterior el interpretar el formato y esos datos para darle un envase más legible. Más o menos algo como esto:
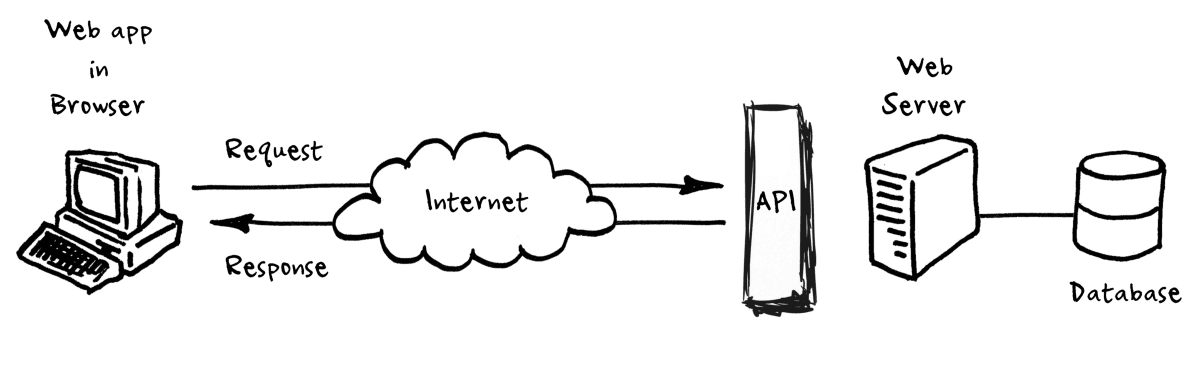
¿Qué es Hubspot?
Posiblemente la definición más extendida de Hubspot sea la de CRM. O quizás la de plataforma de Inbound Marketing. Y yo, que llevo ya casi 3 años trabajando prácticamente a diario con la herramienta os puedo decir que las dos definiciones me encajan. Porque Hubspot es un gestor de contactos y a la vez es una herramienta de marketing. Y lo bueno de Hubspot es que ha sido capaz de incorporar servicios que no se acostumbran a ver en herramientas de este tipo, como analítica web o predicciones sobre tu generación de contactos y, a la vez, te permite gestionar campañas de emailing o crear una web desde 0. Es un all-in-one del marketing.
Y, aunque su interfaz de usuario es muy completa, es muy posible que para algunas tareas se nos quede corta. Bien porque no podamos extraer la información necesaria de forma manual en esta interfaz, bien porque hacerlo sea demasiado costoso o bien, simplemente, porque queremos extraer una información para cruzarla con datos propios de otro sistema. Aquí es donde entrará el uso de su muy bien documentada API. La podemos encontrar aquí.
Definición del problema
Voy a poneros un ejemplo con un esquema parecido a otro que me ocurrió en el mundo real. Aquí exageraremos todo para hacerlo más comprensible y didáctico. Tu empresa, que se dedica a fabricar cortinas exclusivamente del material vantablack lleva varios años utilizando Hubspot como su herramienta de campañas de emailing. Lo que les ocurre es que quieren ver tanto el rendimiento como la interacción que tienen sus usuarios con todos los emails que han ido enviando durante este periodo.
¿No ofrece Hubspot este tipo de información? La ofrece, pero aquí tenemos dos problemas: la ofrece parcialmente de forma agregada y nuestro cliente negruzco ha estado realizando muchas customizaciones a sus envíos (por ejemplo, ha querido introducir un botón para darse de baja que se traga la propia luz cuando lo clicas), por lo que Hubspot no es capaz de ofrecer la información que necesitan de forma ordenada, al no reconocerla como lo que ellos esperan.
Por tanto, para la resolución de nuestro problema necesitamos dos ingredientes: los datos estadísticos estándares de los correos por un lado (aperturas, clicks, CTR, etc) y por otro, los clicks en los diferentes elementos que componen el email. Con esto último podremos saber tanto si los usuarios se dan de baja más en algún tipo de envío y también, por ejemplo, qué tipo de contenido es el que más interacciones atrae.
Primera llamada a la API de Hubspot
Una vez entendido nuestro problema conceptual, nos podemos poner manos al código. Lo primeroprimerísimo que vamos a necesitar es la forma de autenticarnos como gente respetable que puede utilizar la API de Hubspot. Para ello existen dos maneras: a través del OAuth o APIKey. La manera que vamos a ver aquí es la última, utilizaremos la APIkey proporcionada por nuestro cliente para acceder al interior de sus datos, pero os dejo por aquí cómo configurarlo exactamente lo mismo a través del OAuth. Básicamente utilizo la APIkey porque es mucho más cómoda de trabajar.
Voy a dar por hecho una serie de cosas que son necesarias para seguir trabajando, pero que creo que son elementales y, si no sabes hacerlo, es mejor que empieces a trabajar por ahí antes de ponerte con este tipo de procesos. Estos requisitos son los siguientes (adjunto documentación para ponerse a trabajar!):
–Trabajar con un editor de código (yo utilizo Atom, pero cada uno el suyo).
–Crear un entorno de trabajo virtual con python (lo que comúnmente se conoce como «env»)
–Tener cierto conocimiento de programación (ojo, no se necesitan conocimientos avanzadísimos para esto, pero un mínimo para seguir la guía)
-Crear tres directorios en env que sigan esta lógica: env/emails_directory, env/emails_statistics y env/email_click_events
Creo que con esto estarían todos los prerequisitos. Dicho esto, ya podéis clonaros mi repo con todo el código para ir trabajando sobre lo que vayáis leyendo, pero iré desgranándolo en secciones más pequeñas para tener toda la información de la manera más clara. Vayamos ahora a preparar nuestro código para realizar la primera llamada a la API de Hubspot.
Asumo que ya tenéis la APIKey de Vantablack, así que vamos al grano. Mi forma de trabajar con credenciales de este tipo es almacenarlas en un archivo dentro de una carpeta llamada «credentials» y que ésta esté gitignorada. A través de este procedimiento conseguimos trabajar con nuestra credencial sin correr el riesgo de publicarla accidentalmente. Por otro lado, vamos a trabajar a través de un entorno virtual de python, como ya he comentado anteriormente, por lo que una vez clonado el repositorio, ejecutaremos este código a través de nuestra terminal en la carpeta contenedora:
python -m venv env
De esta manera, instalaremos todas las dependencias de python de un solo golpe. Por otro lado, para tener todas las librerías necesarias a la hora de trabajar el paquete, ejecutaremos lo siguiente:
env\Scripts\pip install -r requirements.txt
Todo esto nos va a permitir de forma mucho más ágil a partir de este momento, ya que sólo vamos a tener que preocuparnos de nuestro código. Por tanto, ahora sí vamos a revisar nuestro primer script, desde el que realizaremos la llamada a Hubspot para obtener los ids de todos los emails de la compañía. Esto nos servirá para realizar un primer filtrado y conseguir las estadísticas de estos identificadores. Si habéis clonado el repo sin problemas, habéis creado el folder de env (para tener nuestro entorno virtual) y habéis creado ya la carpeta de credentials en el root del mismo, la estructura de archivos debería parecerse mucho a esto:
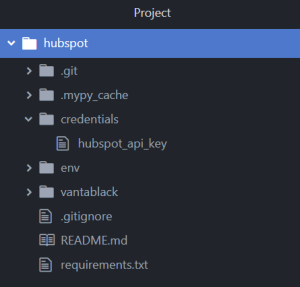
No os preocupéis por ahora de la carpeta de .mypy_cache. El resto debe estar tal y cómo os muestro en pantalla. Si es así, continuemos. Nuestro primer script para coger contacto con Hubspot y su API va a ser el que hemos llamado «email_ids_to_file» dentro del folder «vantablack». Lo que os encontraréis es este código de aquí:
import argparse
import urllib.parse
import json
import os
from typing import Any, Dict, List
from vantablack import utilities
def email_ids_to_file(directory: str, data: Any) -> None:
#creating the file with email ids
filename = "emails_ids.json"
path = os.path.join(directory, filename)
with open(path, "w") as f:
return json.dump(data, f)
def getting_all_email_ids(api_key: str) -> List:
#calling hubspot api to get the information that we want
emails_list: list = []
limit = 100
get_all_emails_url = "https://api.hubapi.com/marketing-emails/v1/emails?"
#publish date greater than 30th June 2018 to not retrieve data from draft emails
parameter_dict = {'hapikey': api_key, 'limit':limit, 'publish_date__gte': 1530309600000}
parameter_dict['offset'] = 0
headers: Dict = {}
# Paginate your request using limit
while True:
parameters = urllib.parse.urlencode(parameter_dict)
get_url = get_all_emails_url + parameters
r = utilities.get_with_retries(get_url, headers, 2, 3)
response_dict = r.json()
emails_list.extend(response_dict['objects'])
if response_dict["offset"] >= response_dict['total']:
break
else:
parameter_dict['offset'] = response_dict['limit']+response_dict['offset']
ids: List = []
for item in emails_list:
if 'campaignName' in item:
if item['isPublished'] == True and item['ab'] == False:
ids.append(str(item['id']))
print("list from ids has {} results".format(len(ids)))
return ids
def dump(directory: str, api_key_path: str) -> None:
#dumping all the email ids to a file
api_key = utilities.load_api_key_from_file(api_key_path)
email_ids = getting_all_email_ids(api_key)
email_ids_to_file(directory, email_ids)
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description="create a file with all email ids."
)
parser.add_argument(
"--directory",
required=True,
type=str,
help="path to directory to write the files")
parser.add_argument(
"--api_key_path",
required=True,
type=str,
help="path to credentials")
args = parser.parse_args()
dump(args.directory, args.api_key_path)
No os preocupéis por verlo todo de golpe, vamos a ir desgranándolo poco a poco y así tendremos claro por qué y para qué estamos utilizando cada parte del script. Vayamos a las primeras 6 líneas, que se encargan de realizar las llamadas oportunas a las librerías que vamos a ir utilizando en nuestro código:
Argparse: este módulo nos va a permitir generar una serie de argumentos a la hora de llamar al script de forma global. Esto hace que sea mucho más fácil de leer por un humano y que se entienda la utilidad de cada uno de esos argumentos. Lo veremos más en profundidad en la parte de la función main.
Urllib.parse: utilizaremos esto para convertir nuestros parámetros (los que sean) en un formato que pueda ser pasado como url. Esto es imprescindible para la llamada al endpoint de la API.
json: este es el formato que nos va a devolver la API y necesitaremos este módulo para hacerlo legible y poder manipularlo debidamente.
os: este módulo nos permitirá trabajar con las rutas de fichero, algo que haremos más adelante y que nos sera muy útil a la hora de manipular los datos.
typing: este módulo es fundamental a la hora de marcar el tipo de input y output que vamos a obtener en cada caso. Esto nos ayuda a saber con qué trabajamos en cada momento y cómo debemos manipularlo. Esto, a su vez, es imprescindible para realizar test estáticos. Como esto es algo quizá más complejo que la propia llamada de API, lo dejaré para una entrada entera. Quedáos con que para realizar estos tests utilizaremos mypy y que gracias a esto podremos detectar si los formatos de los datos son los que esperamos.
utilities: cómo veis, estamos llamando a un módulo de nuestro propio paquete. He creado el script de utilities para albergar herramientas que utilizaremos también en otros scripts, para así no tener que repetir el código en cada uno de ellos. Para este en concreto vamos a utilizar una función que nos devolverá el texto de un archivo (la APIkey en este caso) y otra que realizará las llamadas a la API con una serie de reintentos si alguno de los errores que he especificado ocurre durante esa llamada. Esto lo realizaremos a través de una técnica denominada exponential backoff, que nos permite disminuir el número de llamadas multiplicativamente, llegando a la solución deseada. Esto quiere decir que si nos encontramos con algún error, el código se ejecutará hasta que se agoten las posibilidades expuestas.
Bien, ya tenemos todos los módulos que vamos a necesitar para nuestro script cargados y funcionando. Vayamos ahora sí a nuestras funciones:
def email_ids_to_file(directory: str, data: Any) -> None:
#creating the file with email ids
filename = "emails_ids.json"
path = os.path.join(directory, filename)
with open(path, "w") as f:
return json.dump(data, f)
Esta función, a grandes rasgos, lo que nos va a permitir es una cosa: crear un fichero con la información de un json. ¿Qué quiere decir que va a crear un fichero? Que va a marcar en nuestro ordenador (o el sitio que le digamos) un espacio definido para la información que estamos almacenando. Ese fichero sólo existe una vez y se machacaría si viniera otro fichero con el mismo nombre. ¿Por qué es útil esto para nosotros? Porque en este primer script lo que vamos a generar es un único fichero que va a almacenar todos los ids de los emails existentes en la cuenta de Vantablack. Si hacemos esto programáticamente (ej. una vez al día todos los días), este proceso nos permitirá sobreescribir el fichero ya existente con la nueva información que hemos conseguido. Si queréis más información sobre cómo trabajar con ficheros en python, esto es puede ser de gran utilidad (como siempre).
La siguiente función la voy a descomponer en tres bloques distintos para su mejor manejo, ya que hay que tener en consideración varios factores.
def getting_all_email_ids(api_key: str) -> List:
#calling hubspot api to get the information that we want
emails_list: list = []
limit = 100
get_all_emails_url = "https://api.hubapi.com/marketing-emails/v1/emails?"
#publish date greater than 30th June 2018 to not retrieve data from draft emails
parameter_dict = {'hapikey': api_key, 'limit':limit, 'publish_date__gte': 1530309600000}
parameter_dict['offset'] = 0
headers: Dict = {}
En esta primera parte de la función lo que vamos a construir es la base sobre la que trabajaremos más abajo. Básicamente, generamos todos los parámetros que necesitamos para poder realizar la llamada al endpoint, que se define principalmente por la variable get_all_emails_url. Los parámetros en parameter_dict almacenan por un lado la apikey, el límite de resultados de llamadas (que hemos establecido en 100) y la fecha desde la cual se tiene que tomar los datos. Tanto el límite como la fecha son opcionales, pero he decidido dejarlos para que veáis cómo añadir nuevos parámetros a nuestra url de llamada.
# Paginate your request using limit
while True:
parameters = urllib.parse.urlencode(parameter_dict)
get_url = get_all_emails_url + parameters
r = utilities.get_with_retries(get_url, headers, 2, 3)
response_dict = r.json()
emails_list.extend(response_dict['objects'])
if response_dict["offset"] >= response_dict['total']:
break
else:
parameter_dict['offset'] = response_dict['limit']+response_dict['offset']
Esta parte define esencialmente la llamada que vamos a realizar a la API, a través de la cual obtendremos nuestros datos. En get_url, como véis, lo que hacemos es juntar la url base con los parámetros que hemos establecido más arriba, ya parseados a través de urllib. Esa información, que la almacenamos en r, la pasamos a formato json y lo almacenamos todo en la lista que más arriba habíamos creado para tal efecto. Utilizaremos el offset como indicador de paginación y a través de él, obtendremos todos los resultados disponibles, hasta agotar lo existente en este endpoint.
ids: List = []
for item in emails_list:
if 'campaignName' in item:
if item['isPublished'] == True and item['ab'] == False:
ids.append(str(item['id']))
print("list from ids has {} results".format(len(ids)))
return ids
Por último, aquí realizamos un paso importante: filtramos según una serie de condiciones los resultados y nos guardamos únicamente los ids de los emails que hemos extraído. Estas condiciones son: que el email contenga campaignName (lo necesitaremos más tarde y no queremos ninguno que no lo tenga en este caso), que el email haya sido publicado y que no pertenezca a una campaña A/B. Esto último lo dejo como algo opcional también para que podáis ver cómo aplicar esta serie de condicionantes.
Parece que ya tenemos lista nuestra función de llamada a la API y nuestra función para escribir todo esto en un fichero. ¿Qué nos falta? La función que lo agrupe todo en un único proceso:
def dump(directory: str, api_key_path: str) -> None:
#dumping all the email ids to a file
api_key = utilities.load_api_key_from_file(api_key_path)
email_ids = getting_all_email_ids(api_key)
email_ids_to_file(directory, email_ids)
Esta función, tal y como hemos dicho, lo que hace es exactamente eso: genera un fichero en nuestro ordenador con la información obtenida a través de la dos funciones que ya habíamos desarrollado. IMPORTANTE: lo que he hecho para que no se vuelquen toda esta serie de ficheros en git cuando los creamos es crear carpetas en env que contengan todo esto. Para este caso, lo que haremos será crear el directorio dentro de «env» llamada «emails_directory».
Por último, nos encontramos con la función if __name__ == «__main__». Esto es un built-in de python que vamos a utilizar para determinar el contexto de ejecución de nuestro código, haciendo así que se ejecute el código contenido sólo si el intérprete puede evaluar que __name__ es igual «__main__». De forma algo más sencilla, esto quiere decir que si llamamos desde la terminal a nuestro módulo, se ejecutará todo aquello que le hemos dicho que tiene que ejecutar, nuestro caso, la función dump con los dos argumentos necesarios:
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description="create a file with all email ids."
)
parser.add_argument(
"--directory",
required=True,
type=str,
help="path to directory to write the files")
parser.add_argument(
"--api_key_path",
required=True,
type=str,
help="path to credentials")
args = parser.parse_args()
dump(args.directory, args.api_key_path)
Gracias a argparse, que ya habíamos visto más arriba, somos capaces de generar esta serie de argumentos a través de los cuales vamos a llamar a nuestra función, con muchísima más información de la que tendríamos con unos simples parámetros (tenemos el formato, si es requerido o no, el texto de ayuda…).
Llegados a este punto, lo único que nos falta es probar nuestro código. Si has almacenado el archivo de credenciales tal y como hemos especificado y has creado el directorio env/emails_directory, al ejecutar esto en la terminal, tu código debería funcionar correctamente:
env\Scripts\python -m vantablack.email_ids_to_file^
--directory env\emails_directory^
--api_key_path credentials/hubspot_api_key
Recuerda que si no estás en Windows, deberás cambiar el env\Scripts por env/bin. Et voilà. Si todo ha ido como debía, deberías ver el siguiente fichero en el directorio especificado:
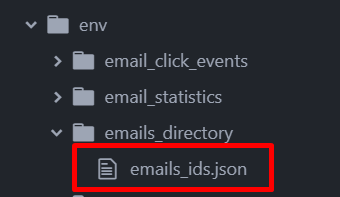
Y así, podemos finalizar nuestra primera parte de la expedición hasta las profundidades de Hubspot. No os vayáis, porque la segunda parte también viene movidita: extraeremos los eventos de email que nos ha pedido nuestro cliente y realizaremos el merge para obtener un csv con el que trabajar.
Enhorabuena por llegar hasta aquí, sé que no ha sido fácil, pero ha valido la pena. Nos vemos en el otro lado.

2 comentarios sobre “API Calls: explorando los datos de Hubspot con python (parte 1)”